Zamlet: A Scalable RISC-V VPU

Summary
An exploratory RISC-V VPU scaling to large numbers of lanes. A 2D mesh is used for lane-lane communication, and the vector data is structured so that data remains local for most operations.
The project is under development. There is a python model for performance simulations, and the beginnings of an RTL implementation.
These docs are all human written. Much of the code is LLM generated with manual revisions, or manually generated with LLM revisions.
Design Goals
- 1) It should scale to large numbers of lanes (1024 or so).
- 2) Should run riscv binaries using the vector extension.
- 3) LLVM should be able to target the hardware (modifications allowed).
- 4) It should be possible to create extremely performant programs.
These goals are often at cross purposes. We require that arbitrary programs should run but do not require they are performant. To get high performance it will be necessary to use custom instructions, specific memory layout and compiler modifications.
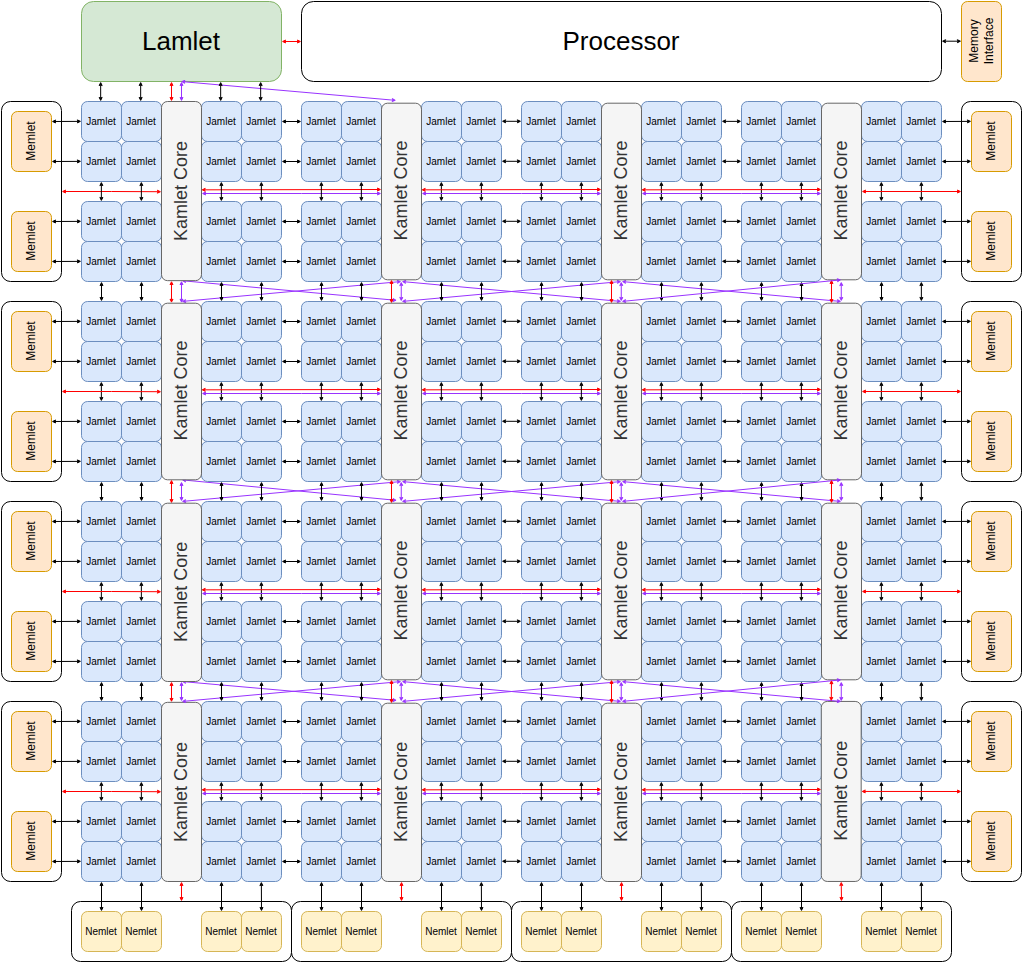
Approach
-
The lanes (jamlets) of the VPU are arranged in a 2D grid and connected with a mesh network.
-
There is an intermediate level of hierarchy between the VPU mesh of lanes and the individual lanes. These groupings of lanes (kamlets) share an instruction buffer, renaming, reordering and other logic.
-
The data is organized into "stripes" of size
n_lanes * word_width, and the ordering of bytes in each stripe depends on the element-width of the data written to it. This ordering means that most operations work with lane-local data. -
A synchronization network allows for fast synchronization between the lane-groupings (kamlets) when required.
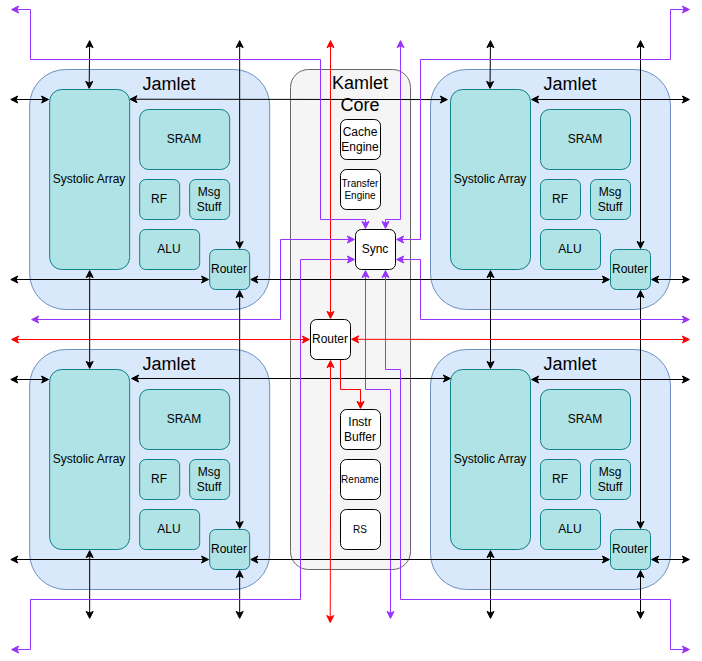
Status
There is a python model that captures roughly cycle-accurate behavior with a focus on modelling the message passing aspects, since that is where the highest risk is. Most of the RISC-V vector extension is supported by this model, and some custom extensions are added to improve performance. My impression so far is that the approach is practical. My main concern is that I'm not capturing the latencies accurately since I don't yet have good estimates.
There is a start on implementing the design in Chisel and some initial area results have been obtained using the skywater130 PDK. I was most concerned that the area cost for producing, receiving and keeping track of message states would be prohibitive, but the initial results suggest that while these costs are significant they are not prohibitive (roughly the same size as 64-bit integer multiplier).
I'm currently focusing on getting an implementation of a single lane solid enough that I can get good estimates of the latencies, and a feel for what the congestion is going to look like.